大模型的尽头是开源




大模型的战争,正悄然换牌。
闭源一度是顶尖玩家的主流选择,视为坚实护城河。然而,2025年9月,阿里、腾讯、百度等大厂几乎同一时间,将模型开源大举摆上牌桌,集中且密集的动作令人关注。
从能看图、能对话,到能写代码、能做3D建模,大厂几乎将压箱底的招数一股脑甩出来。过去以技术封闭构建壁垒的模式正在被打破,取而代之的是将核心模型技术对外开放,结合开发者的集体智慧进行迭代优化,并快速占领开发者心智。
眼下,各类AI需求被拆得越来越细,落地场景也五花八门,而开源也不再是某种技术该不该开放的问题,而是直接成了大厂们硬碰硬的底层功夫。这就像在一场大牌局里,底牌几乎都已经翻出来了,大家手里的牌面差不多,真正决定最后输赢的,就不再是有没有牌,而是谁能打得更巧,谁能留在桌上。
一、开源别做选择题
当腾讯、阿里、百度纷纷甩出大招,将重量级模型陆续摆上台面,重点不仅在于模型本身,更在于大厂们大都选择了开源路线。
表面上看似动作上的巧合,但深入分析,这更像是大厂对市场需求变化所做出的一种共识性反应。开源已不再是可选的附加题,而几乎是必须正面回答的必答题。谁能答得更漂亮,谁就可能在下一局多占一份先机。
据腾讯混元公众号及天眼查媒体综合消息显示,9月28日,混元图像3.0正式发布并开源。腾讯混元公众号介绍称,该模型为“首个工业级原生多模态生图模型,参数规模80B,也是目前测评效果最好、参数量最大的开源生图模型,效果可对标业界头部闭源模型。”两天前的9月26日,混元3D-Omni、混元3D-Part发布并开源。
这一连续出牌,一定程度上可以看作腾讯通过开源来调动外部开发者的力量,让复杂的3D建模、图像生成等任务在更大范围内、更快速地向前推进和完善。
然而,各大厂模型越做越庞大,与其一个人握着手里的牌,不如摊开让更多玩家一起来出招、共建。这样一来,原本孤立的牌面,就可能被拼接成更厚实的成果,推动整场牌局不断升级。
据《新京报》9月24日报道,阿里巴巴在云栖大会上一口气发布了7款模型,包括旗舰模型Qwen3-Max、下一代基础模型架构Qwen3-Next及系列模型等。据通义千问Qwen公众号消息,其已率先开源视觉理解模型Qwen3-VL系列的旗舰模型Qwen3-VL-235B-A22B,同时包含Instruct与Thinking 两个版本。

▲图:通义大模型公众号
而面对多元的产业需求,开源也成为推动技术更快进入实际应用的有效路径。据《上海证券报》9月23日报道,百度智能云千帆宣布推出全新视觉理解模型Qianfan-VL,并全面开源。
该系列模型包含3B、8B和70B三个尺寸版本,面向企业级多模态应用场景,可以说是进行了深度优化的视觉理解大模型。Qianfan-VL具备基础通用能力,也针对产业落地中的高频需求,如OCR和教育垂直场景做了专项强化。
这里释放出的信号是,模型本身是工具,决定能否落地的,是可得性和成本可控性。百度通过对企业级多模态应用场景的需求深挖,某种程度上凸显了其自身的技术攻坚能力,也在降低应用门槛上,让更多企业可以以较低成本接入。
从研发端的集体迭代,再到产业应用的快速落地,一系列动向表明,同时作用于研发和产业两端的开源策略,其战略价值不言而喻,也正逐渐成为大厂发展的关键动力之一。在研发层面,开源将分散的尝试汇成合力。在产业层面,开源则让更多企业能够跨过门槛,将模型真正用起来。
二、驱动未来的引擎
当开发者与企业客户习惯于在某个开源生态中进行开发时,其产生的庞大算力需求、对更高性能的付费版本以及配套的云服务与行业解决方案的依赖,有望自然汇入大厂的商业河流。开源,就这样从一张亮出的牌,变成了整个牌局继续运转的引擎。
技术演进与应用落地的双轮驱动,牌桌的规则正被改写,对于旨在构建广泛生态的大厂而言,开源似乎已无悬念,真正的问题是能开源到什么程度。大厂选择将底牌摊得更大、更全,不是炫技,而是试图让市场与产业习惯于围绕自己的生态来运转。
共识既已形成,接下来的赛点是比较谁开源的尺度更为拉满,给的是更多干货。
拉满,不是单纯将参数堆到天花板,而是将模态、场景和应用尽可能覆盖;干货,也不是象征性地开放几个版本,而是摆出一整套可落地的模型能力组合。这样的开源,不是让开发者挑不出缺口,而是要让上下游产业明确感受到,这是一种确定性的开源,不仅能用,还好用。
天眼查媒体综合信息显示,阿里通过提供大规模、多模态的模型矩阵,满足不同开发者的需求。其战略意图或在于,让阿里的模型库成为开发者的优先选择。据《经济观察网》9月29日报道,阿里通义系列已经累计开源超过300个模型,下载量突破6亿次,衍生模型超过17万个。
腾讯和百度则有所分化。从腾讯混元公众号公开的消息内容看,腾讯的开源重点看上去是放在了展现其差异化能力上。进而,无论是复杂的3D生成,还是高语义要求的图像创作,这一开源举措,有助于腾讯在专业创作者和相关企业客户心中建立强关联。
百度则给人一种主打软硬一体组合拳的阵势,将模型与自研昆仑芯P800计算卡深度绑定。据《上海证券报》,昆仑芯P800提供了强大的算力支撑,确保模型能够高效处理海量数据与复杂算法,同时支持单任务5000卡规模的并行计算。
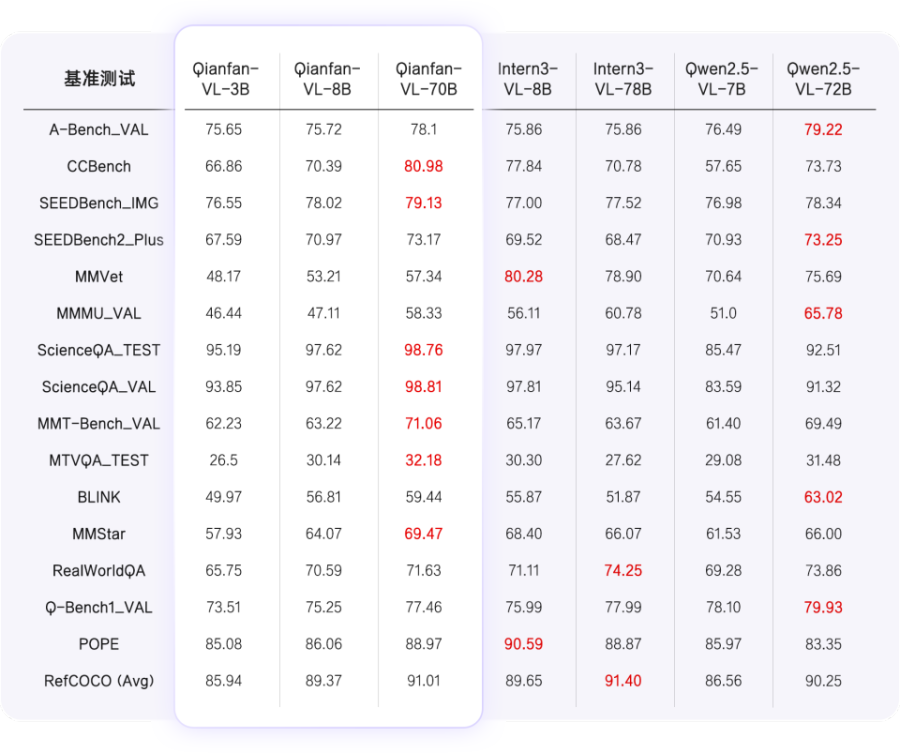
▲图:百度智能云千帆官方公众号
报道指出,“在通用能力基准测试中,Qianfan-VL系列模型(3B、8B、70B)展现出显著核心优势。从视觉理解到专业领域问答,模型性能随参数规模增大提升显著”。
尽管大厂们开源策略各有侧重,但体现出明确的行业趋势,开源不再是点到为止的小修小补,而是大厂们抛出全干货的开放姿态。看似风格各异,实则目标同一。大厂们力求尽可能将开源尺度拉满,不只是实力的展示,也是信心的释放。
然而,将干货拱手相授,只是上半场的局。
真正决定成败的下半场,在于谁能将这些开源的能力转化为产业入口和使用黏性,让开发者、企业客户在不知不觉间依赖于大厂的云基础设施、API以及深度定制的企业级服务。
三、大厂竞技换牌桌
随着顶尖模型能力通过开源逐渐成为公共资源,大厂们的战争,悄然更换了牌桌。技术层面的准入差距正在缩小,行业的焦点急剧转移,接下来的比拼,不再是技术本身的优劣,而是生态的广度和深度。
要在这场新的生态竞争中胜出,阿里打造庞大模型矩阵的长期目标,或可能是将通义模型库打造为AI开发的基础性平台。例如,开发者在处理相关任务时,是否会习惯性地前往其模型库寻找解决方案。
不同于阿里,腾讯的做法或是依托于其庞大的内容生态与社交应用积累,在相关领域建立优势。譬如,其在游戏、社交等领域拥有深厚的根系,对高复杂度、高表现力的3D内容和图像有着天然的内生需求。而通过将开源重点放在3D生成和图像创作上,或是要将其差异化能力摆上桌。

▲图:腾讯混元公众号
这不仅是技术实力的展示,更像是一种生态的顺势而为。当外部开发者,尤其是游戏开发者、动画师和设计师,如果将混元模型深度嵌入其创作流程时,腾讯或将在某种意义上实现从工具提供者到数字内容生产规则制定者的跃迁。这种路径一旦站稳,所带来的用户黏性和生态壁垒往往更难被替代。
而百度的路径,看上去是要基于其作为搜索巨头和AI先行者对算力与稳定性的长期优势,将模型开源与自研昆仑芯P800计算卡深度绑定,形成技术路线的自然延伸。进而,打造从芯片、框架到模型应用的完整生态,这对政务、金融、教育等百度早已布局的重要场景而言,相对更为友好。
换言之,百度要做的,或是将经过深度优化的模型能力和可靠高效的算力支撑同步开放给目标客户和开发者,降低试错和整合成本。通过这种生态构建,百度的竞争力便也不再停留在模型层面,而是在产业服务上扎根更深。
这些差异化的布局,说明大厂们的大模型竞争正转换风向,它们并非在全新的战场上从零开始,而是将自身固有的核心优势,通过开源战略投射和放大到大模型的疆域之中。
过去看谁的团队更大、投入更多,如今比的是谁能将自身优势转化为生态吸引力,让开发者在特定场景下最先想到“就用它”。开发者一旦习惯了某套开源模型,企业客户在搭建应用时自然就会跟上,这套系统便有望成为事实上的“王牌”。
四、写在最后
从开源是否做选择题,到日趋尺度拉满的干货,再到牌桌换新的生态竞争,中国大厂的大模型路径已经显现出某种确定感。大厂不再满足于单一产品的比拼,而是通过一次次开源,将竞争延伸到更广阔的开发者社群与行业场景中。
尽管闭源在特定领域仍有价值,但就构建广泛产业影响力而言,开源无疑已成为大厂大模型战略的必然归宿和主战场。未来几年,大模型的竞争会愈演愈烈,开源让技术门槛降低,但也让竞争提前白热化。
真正的胜负,不是今天谁先开源了多少,而是谁能在开放之后,将开发者、行业客户和应用场景都拉进自己的生态之中。惟其如此,才能在新的牌桌上占据主动。大厂的大模型之战,终究不是看谁先出完手里的牌,而是谁能让更多人心甘情愿地跟着出牌。
作者|林飞雪
编辑|何坤
运营|陈佳慧
出品|零态LT(ID:LingTai_LT)
头图|网络公开用图
