拿了30个冠军的腾讯翻译模型,实际表现又如何?



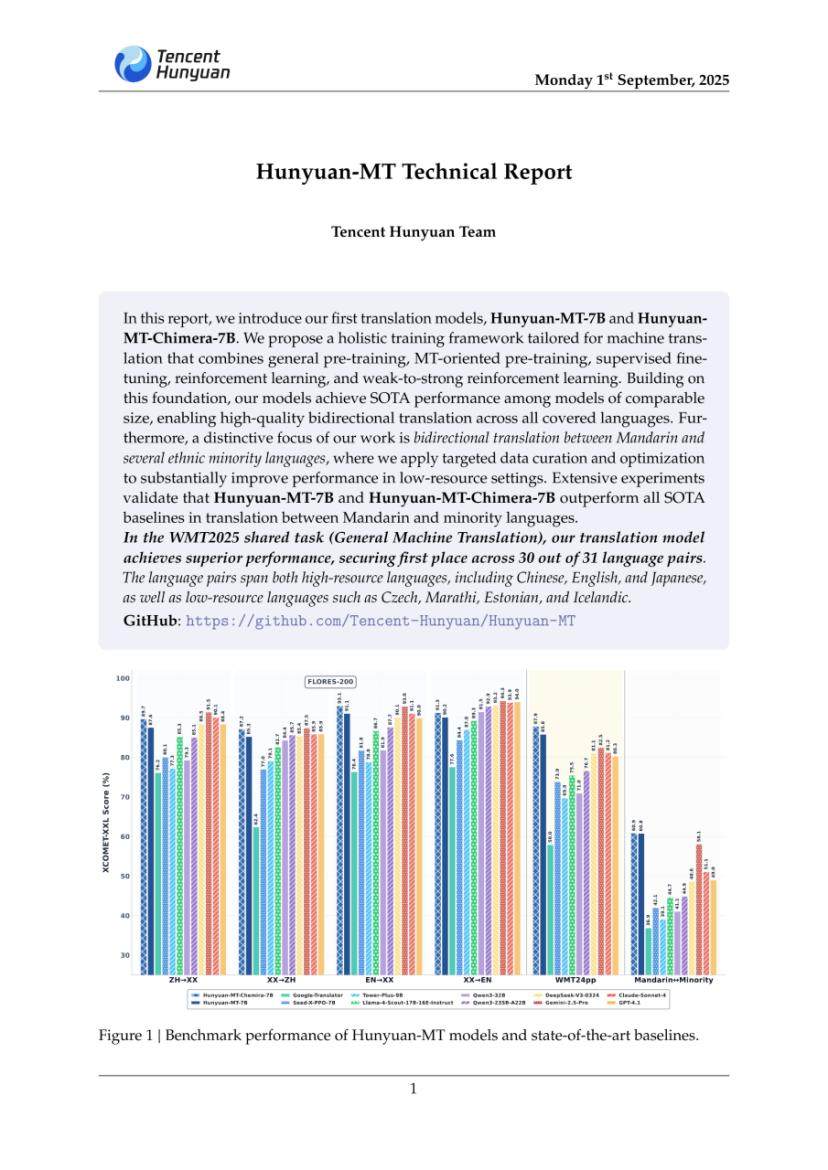
腾讯在Hugging Face上发布了一个专门用来翻译的模型,叫做Hunyuan-MT-7B。根据它的官方介绍,这个翻译模型在WMT25竞赛中,该模型在参与的31个语言类别中有30个获得了第一名。并且在同等规模模型中实现了行业领先的性能。
而Hunyuan-MT-7B的集成模型Hunyuan-MT-Chimera-7B,是业界首个开源翻译集成模型,将翻译质量提升至新高度。所谓集成模型,是指一种机器学习方法。它的核心思想是,不依赖单个模型进行预测或判断,而是将多个模型的预测结果结合起来,从而获得比任何一个单一模型都更好、更稳定的最终结果。
那么回到翻译这个事上来,Chimera的逻辑就是让MT-7B翻译系统生成多个不同的翻译候选版本,会分析这些候选版本,将它们各自的优点整合起来。最后,生成一个质量超越了任何一个单一候选版本的、更优的最终译文。
但是由于官网目前只有MT-7B这一种版本,因此本文只对该版本进行了测试。
01
这里我使用的都是很常见的英语台词,出自各种经典读物。
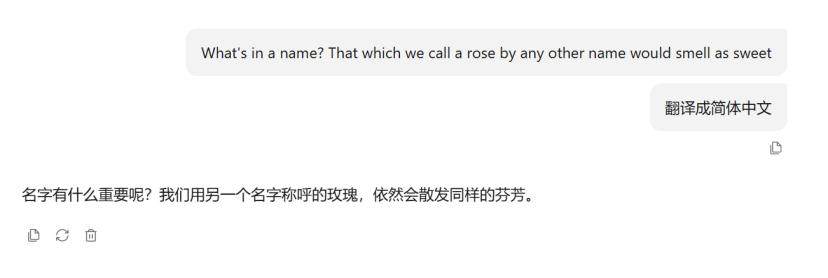
出自《罗密欧与朱丽叶》,原文通常被翻译为“姓名算得了什么?我们所称的玫瑰,换个名字还是一样芳香”。

出自《双城记》,这个翻译的非常精准。
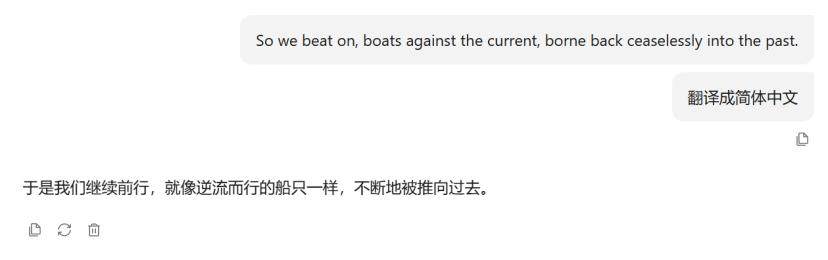
出自《了不起的盖茨比》,同样也翻译得非常精准。
接下来,提高难度,我开始用一些现代英语台词来测试模型的翻译效果。
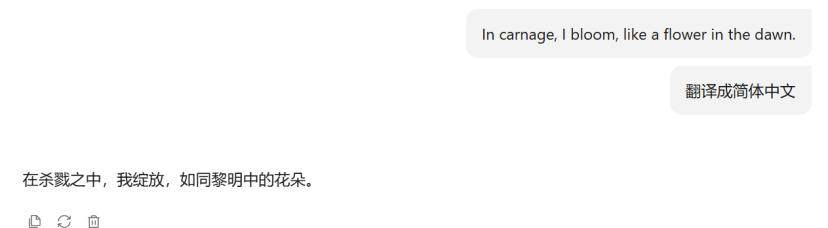
这句话是《英雄联盟》戏命师 烬的选定语音,我于杀戮之中盛放,亦如黎明中的花朵。
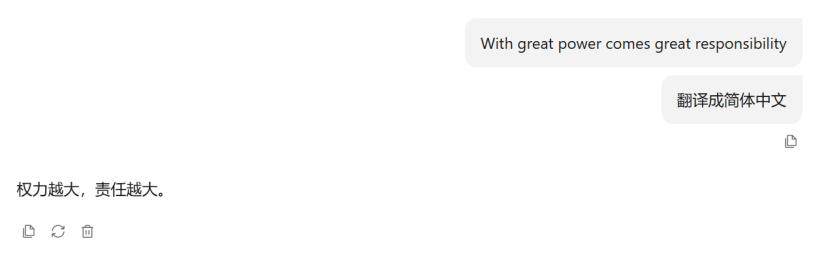
这句话来自电影《蜘蛛侠》,通常我们翻译成“能力越大,责任越大”。
既然英语差不多没问题,就来试试日语和韩语。
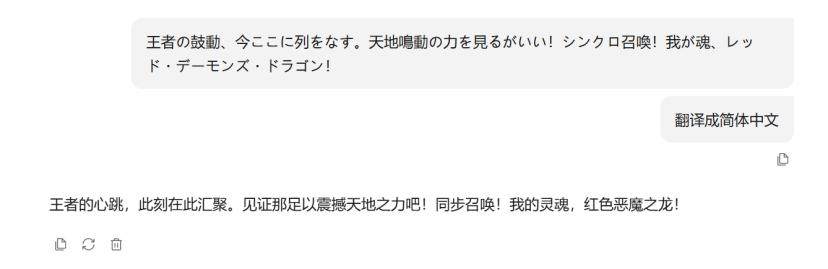
这是《游戏王5D'S》红莲魔龙召唤台词,王者的鼓动,现在于此列成阵势!看着这天地鸣动的力量吧!同调召唤,吾之魂,红莲魔龙!日语中的鼓動(こどう)并非全部都是心跳的意思,也可以指脉动、律动、震动等等。
今ここに列をなす,要拆分出来理解。其中“今”代表此时此刻,“ここに”是在这里,指的是地点,“列をなす”是组成一列,而混元将其简单译作“此刻在此汇聚”并不是很合适。
在韩语方面,Hunyuan-MT-7B也表现得不错。
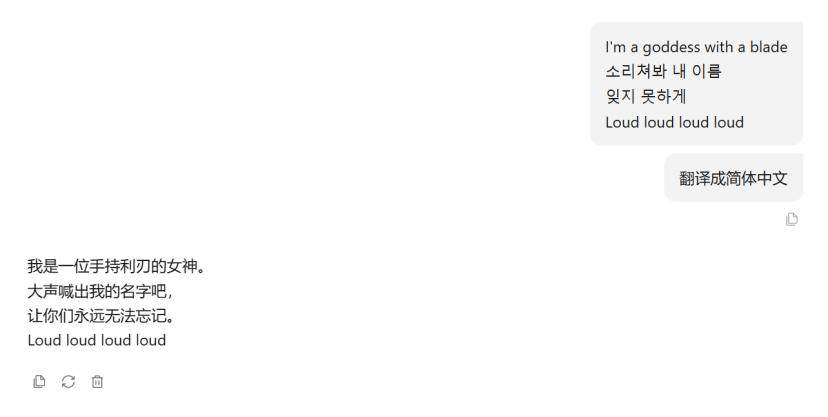
这是K/DA歌曲《POP STAR》中阿卡丽(田小娟)的第一句歌词,即便是英语和韩语混杂,MT-7B翻译得依然非常准确。
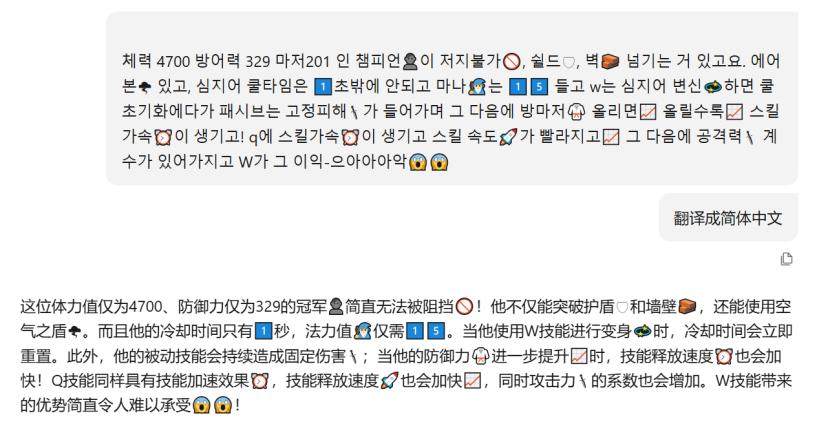
如果带着Emoji一起翻译,那么混元MT可能会出现吞字的情况。比如图中的许秀亏桑提圣经,混元没有翻译出마저201。마저 是 마법 저항력的缩写,마법是魔法,저항력是抵抗力,因此 마저201 的意思是魔法抗性是201。
02
从官方发布的技术报告来看,腾讯混元MT设计的目标是提供高质量的多语言互译能力,现阶段支持包括中文、英文、日文以及哈萨克语、维吾尔语、蒙古语、藏语等5种中国少数民族语言在内的33种语言之间的双向翻译。
混元MT的构建采用了一套完整的、系统化的训练框架,这个框架将模型的训练过程分解为几个前后衔接的阶段,旨在逐步提升模型的翻译能力。整个流程从未经特定任务训练的基础模型开始,通过一系列专门针对机器翻译的优化步骤,最终产出具备专业翻译能力的模型。
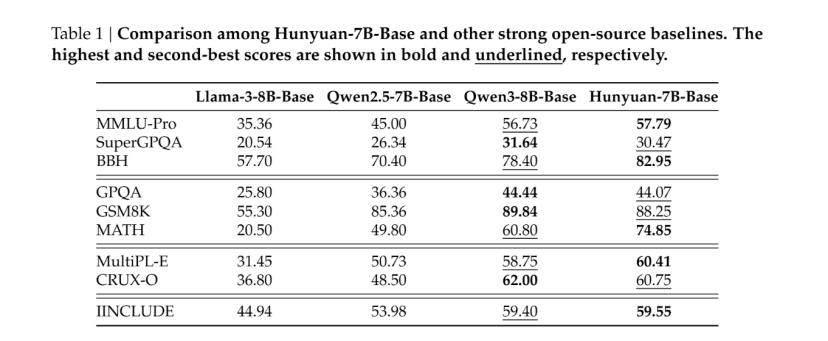
训练流程的第一个环节是通用预训练。这个阶段的目标是构建一个具备广泛知识和多语言基础理解能力的基座模型,即Hunyuan-7B-Base。在训练过程中,模型学习了包含中文、英文以及其他多种语言在内的数据,其中非中英文的多语言数据量达到了1.3万亿个tokens。
为了确保训练数据的质量和多样性,研发团队建立了一套数据质量评估体系。该体系从知识价值、真实性和写作风格三个维度对文本进行打分,并根据数据来源的特性,对不同维度的权重进行调整。比如翻译专业知识的网站,就会优先选择知识价值得分高的数据。
同时,为了保证内容覆盖面的均衡,还建立了学科、行业和内容主题三个层面的标签系统,用以调整不同领域数据的比例,并过滤掉低质量或不相关的内容。通过这一阶段的训练,Hunyuan-7B-Base模型在通用知识、逻辑推理、数学、编程和多语言能力上奠定了基础。
接下来的第二个环节是面向机器翻译的预训练。这个阶段在通用基座模型的基础上,加入了大量为翻译任务筛选的单语和双语语料,目的是使模型的能力向翻译领域倾斜和深化。单语数据主要来源于mC4和OSCAR等公开数据集,并经过了严格的清洗流程,包括语言识别、文档级别去重以及使用语言模型过滤掉高困惑度的低质量文本。
双语平行语料则来自OPUS和ParaCrawl等公开数据集,团队使用CometKiwi等无需参考译文的质量评估工具进行筛选,以保证句对的质量。为了确定不同来源数据的最佳混合比例,团队采用了一种名为RegMix的策略,通过在小规模模型上进行实验,找到能够使训练损失最小化的数据配比,并将其应用于正式的训练中。
此外,为了防止模型在学习新知识时遗忘通用预训练阶段学到的能力,训练数据中还包含了20%的原始预训练语料作为重放数据。
完成两个预训练阶段后,模型进入第三个环节,即后训练阶段。这一阶段通过监督微调(SFT)和强化学习(RL)等技术,将模型的翻译能力进行精细化调优和对齐。监督微调分为两个步骤。第一步使用约300万句对的平行语料,旨在增强模型的基础翻译能力和遵循指令的能力。
这些数据来自多个来源,包括Flores-200开发集、往年的WMT评测测试集、人工标注的中文与少数民族语言互译数据集,以及使用DeepSeek-V3-0324模型生成的合成数据。数据同样经过CometKiwi和GEMBA等质量评估指标的筛选。第二步则使用一个规模更小但质量更高的数据集(约26.8万句对)对模型进行进一步的精炼。这些数据经过了更严格的筛选过程,并对多轮评估中得分一致性较差的样本进行了人工校验。
监督微调之后是强化学习阶段。机器翻译任务的输出具有语义多样性,难以用简单的规则进行评估,这为强化学习的应用带来了挑战。为解决此问题,混元MT采用了GRPO算法,并设计了一个复合奖励函数。
该奖励函数包含三个部分:第一部分是质量感知奖励,使用与人类译员判断高度相关的XCOMET-XXL评分和基于DeepSeek-V3-0324模型的GEMBA框架评分,共同评估翻译的整体质量;第二部分是术语感知奖励,它利用词对齐工具提取源文和译文中的术语等关键信息,通过计算二者的重合率来奖励模型,促使模型更关注专业术语的准确翻译;第三部分是重复惩罚,用于检测和惩罚模型在训练后期可能出现的重复输出,以维持生成内容的多样性和训练的稳定性。
经过这一系列后训练流程,最终产出的模型即为Hunyuan-MT-7B。
03
在Hunyuan-MT-7B的基础上,系统还构建了Hunyuan-MT-Chimera-7B模型。该模型采用了一种弱到强的强化学习方法。正如前文所述,其核心思想是在推理时,首先生成多个不同的翻译候选结果,然后利用一个基于Hunyuan-MT-7B训练的融合模型,将这些候选结果的优点整合起来,生成一个质量超越任何单一候选结果的最终译文。
这个融合模型的训练同样使用强化学习,其奖励函数由XCOMET-XXL评分、DeepSeek-V3-0324评分和重复惩罚项构成。这种方法有效地利用了集成学习的优势,在不增加基础模型参数量的情况下,进一步提升了翻译的上限。
在性能表现上,混元MT系统在多个公开评测基准上进行了测试。结果显示,无论是在WMT24pp还是FLORES-200等通用翻译测试集上,7B参数规模的Hunyuan-MT-7B和Hunyuan-MT-Chimera-7B,其翻译质量均超过了现有的同等规模开源模型,也优于一些知名的商业翻译系统和参数量远大于它的通用大模型。
特别是在中文与少数民族语言互译这个方向上,混元MT的表现显著优于所有其他对比模型,这体现了其在低资源语言翻译方向上的针对性优化取得了成效。人工评测的结果也证实了这一点,在包含社交、邮件、购物、导航等多个生活场景的中英互译测试中,Hunyuan-MT-7B的翻译质量与Gemini-2.5-Pro、DeepSeek-V3-0324等顶尖的大型模型处于同一水平,表明通过面向翻译任务的系统性优化,中等规模的模型同样可以达到很高的翻译水准。
